今天開篇,小T想先和大家討論一個問題:
如果一家企業想要構造一個數據分析模型,來解決現實的業務問題,這個工作需要幾個人來完成?
傳統的答案常常是: 整條業務線的員工
一般來說,業務分析模型的設計是個看似簡單其實復雜的工作。雖然整個數據分析應用的構建過程無非就是數據接入、數據預處理、數據模型構建與評估、模型部署4個步驟,但這4個環節卻需要至少3個不同崗位的員工分工配合才能完成:
?業務人員負責定規則
?數據分析人員負責模型落地
?IT開發人員負責集成到系統中
一來二去,工作效率也在層層溝通中變得越來越慢。如果想要簡化這一整套工作流程,最好是可以讓業務人員來進行數據處理和分析的相關工作,畢竟數據分析模型是根據實際業務流程來構建的,當然是讓最懂業務的人直接上手最方便高效。
但是大部分業務人員在做數據分析構建時,往往會直接卡在數據預處理這一步,難道不懂編碼在數據的世界就真的寸步難行?
數據預處理 到底難在哪兒?
數據質量在數據分析中的重要性毋庸置疑,因此在數據建模中,數據預處理是最重要也最復雜的一環。
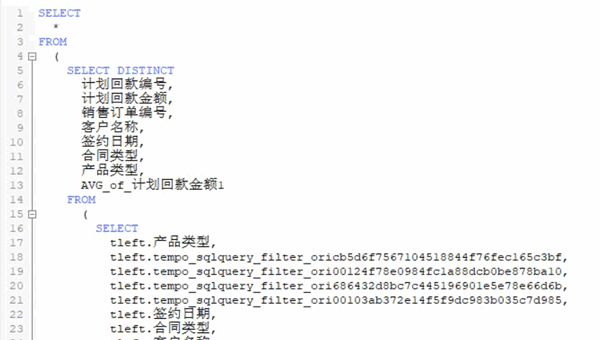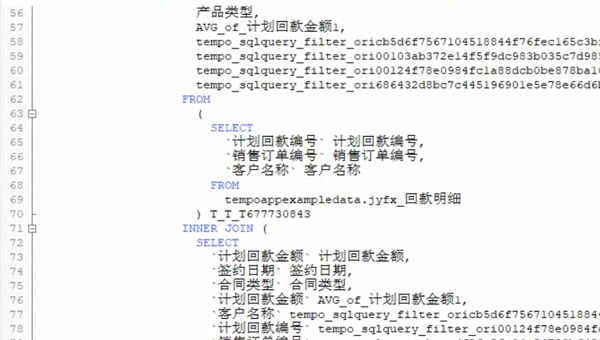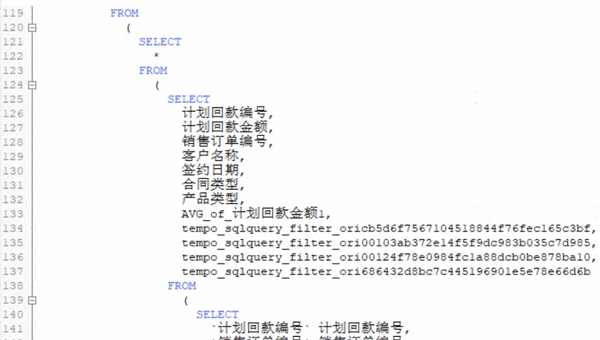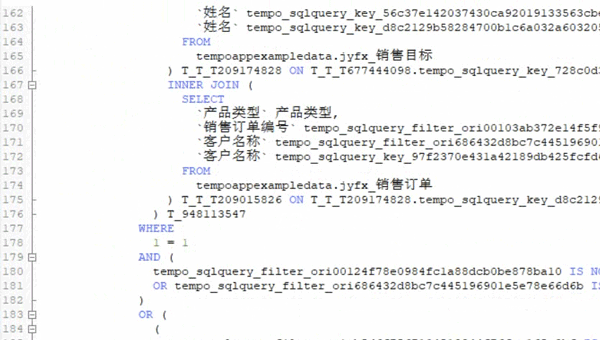
在實際的企業工作場景中,由于業務數據標準不一,在數據分析過程中,還要做相應的處理工作,包括數據連接、過濾、屬性構造、分類匯總、去重、排序等等,這些工作通通都需要使用SQL編程語句進行處理,編寫調試過程至少需要3-4個小時,大約200多分鐘才能完成。
▲傳統數據預處理流程中一定會出現的
長長長長長的SQL語句列
而如果是讓業務人員自己嘗試進行數據處理,基本上都會被以下三道難關直接勸退:
⇒技術門檻高
學會SQL等編程語言對于大部分沒有IT基礎的業務人員絕對不是一件容易的事,而在實際工作中,常常還要跨數據源使用SQL進行數據處理,難上加難。
⇒執行效率慢
現實中,業務數據的數量較為龐大,企業需要一次性接入數據源中的多表,導致數據量及數據維度較大,串行處理執行效率較慢,影響整體流程性能。
⇒復盤效率低
業務流程越復雜,對應的SQL語句也會越寫越長,等到復盤整個分析過程時,面對“SQL套SQL”的長達幾百頁的編碼界面,很難快速梳理分析思路。
針對以上困境,Tempo AI推出了超級數據處理算子功能,幫助普通業務人員在無需掌握SQL語句的前提下,通過可視化操作、無需編碼就可進行數據處理,大大提高數據處理的效率。
化繁為簡 2分鐘搞定數據處理
Tempo AI中的超級數據處理算子功能,分為輸入查詢分析器和過程查詢分析器兩部分。
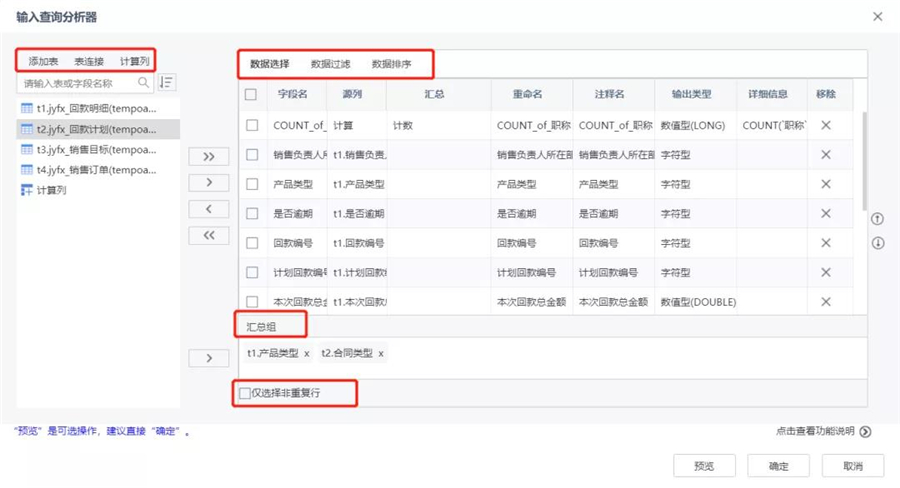
輸入查詢分析器
主要是將庫中數據接入進來進行查詢分析,對數據快速進行過濾篩選,保留滿足條件的數據作為建模數據源,提高流程的執行效率;
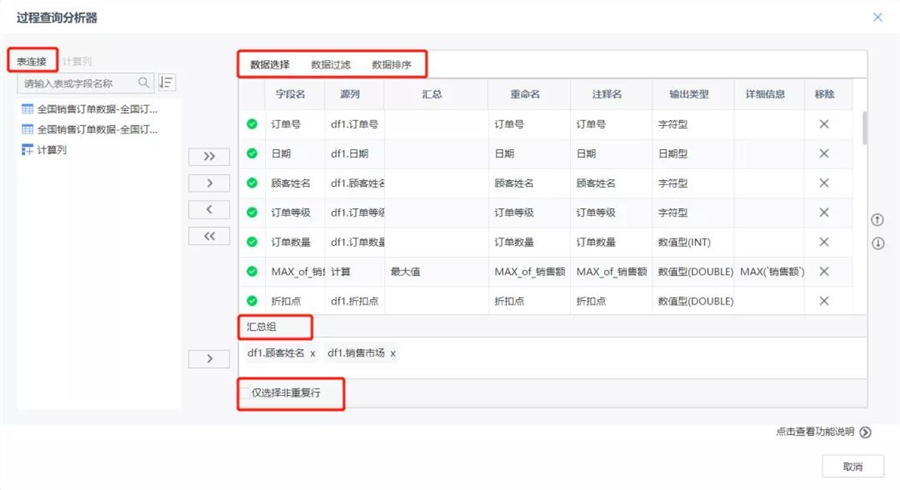
過程查詢分析器
主要是在建模過程中,對數據進行篩選,過濾,匯總、排序等,滿足用戶所需的多種組合算子功能,方便用戶進行建模處理操作。
有了這兩個查詢分析器,普通業務人員就可以直接通過拖拉拽的方式,通過可視化操作界面,根據業務流程,直接在平臺中選取使用超級數據處理算法,快速完成模型的構建,全程不需要進行任何編碼。對比傳統流程動輒半天的工作時間,有了超級數據處理算子的幫助,業務人員一個人只需要2分鐘就可以完成相關操作,大大提升了數據處理的效率。
除了降低技術門檻和提高工作效率,超級數據處理算子還可以簡化數據處理流程,讓數據分析邏輯更加一目了然。
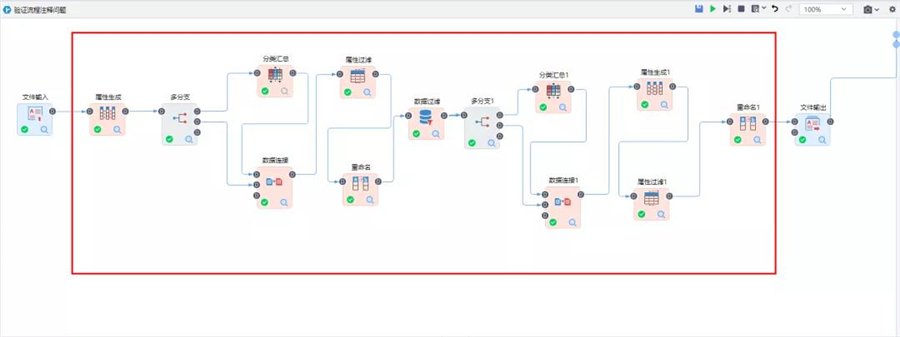
以往在Tempo AI中要完成同構數據源的接入到處理,需要20+個算子來完成,現在僅需4個輸入查詢分析器即可完成。之前對于異構數據源進行數據處理需10+個節點,現在僅需1個過程查詢分析器。節點變少了,梳理復盤自然更順暢。
尤其在解決復雜業務問題的場景中,超級數據處理算子的價值更加能夠得到凸顯。
舉個例子,某保險企業希望利用數據分析手段快速識別業務違規行為,構建業務風控模型。如果使用傳統方法,整個過程需要業務人員和數據分析師及開發人員聯合推進,投入至少數周的時間才能完成。而在應用超級數據處理算子之后,大大降低了數據預處理的難度,簡化了建模流程,業務人員只需2-3天就可以獨立完成模型構建工作,讓整個項目實現了低技術門檻、高執行效率的轉變。
現如今,很多企業都想要建立“人人可做數據分析”的工作文化,但編程等專業技術門檻卻成為了廣大非IT專業出身業務人員體驗數據分析的攔路虎。
在小T看來,其實企業數字化轉型并不意味著要全盤推翻過往,數據分析應該成為業務人員提升工作效率的助力,而不是變成一線員工額外的負擔。因此,企業在選擇數據分析工具時,應該要特別注意產品的易用性。
Tempo大數據分析平臺在設計研發之初,就考慮到了企業的實際應用場景,不斷提升產品的易用性,致力于打造面向“全民數據科學家”的人工智能分析與應用構建平臺,助力AI時代數據化運營。如果想要體驗便捷易用好入門的數據分析工具,歡迎申請試用。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺









 陜公網安備 61019002000171號
陜公網安備 61019002000171號



