大話數(shù)據(jù)挖掘——預(yù)測(cè)分析之決策樹(shù)方法
2021-03-02 18:18:58
次
接上一篇《大話數(shù)據(jù)挖掘之預(yù)測(cè)分析》
徐教授的PPT又翻開(kāi)了新的一頁(yè),他將光筆指向屏幕上的樹(shù)狀圖,講道:“所謂決策樹(shù)就是一個(gè)類(lèi)似流程圖的樹(shù)型結(jié)構(gòu),樹(shù)的最高層結(jié)點(diǎn)就是根結(jié)點(diǎn),樹(shù)的每個(gè)內(nèi)部結(jié)點(diǎn)代表對(duì)一個(gè)屬性(取值)的測(cè)試,其分支就代表測(cè)試的每個(gè)結(jié)果,而樹(shù)的每個(gè)葉結(jié)點(diǎn)就代表一個(gè)類(lèi)別。從根節(jié)點(diǎn)到葉子節(jié)點(diǎn)的每一條路徑構(gòu)成一條‘IF…THEN…’分類(lèi)規(guī)則。”
李部長(zhǎng)凝視著大屏幕上的決策樹(shù),明白了其中的奧妙,不禁道:“決策樹(shù)方法實(shí)際上就是通過(guò)一定的評(píng)判策略判定哪一個(gè)屬性對(duì)分類(lèi)最為重要,就將其作為根節(jié)點(diǎn),然后再判斷余下的節(jié)點(diǎn)中最重要的的節(jié)點(diǎn),直到葉子節(jié)點(diǎn)。”
“好,理解得還比較透徹。不過(guò),李部長(zhǎng),什么樣的節(jié)點(diǎn)才可以標(biāo)注為葉子節(jié)點(diǎn)呢?”徐教授問(wèn)。
李部長(zhǎng)吱吱唔唔:“好像有三種情況……”
“對(duì),附合以下三個(gè)條件之一的節(jié)點(diǎn)就可為葉子節(jié)點(diǎn):(1)節(jié)點(diǎn)的樣本集合中所有的樣本都屬于同一類(lèi);(2)節(jié)點(diǎn)的樣本集合中所有的屬性都已經(jīng)處理完畢,沒(méi)有剩余屬性可以用來(lái)進(jìn)一步劃分樣本,這時(shí)候采用子集中多數(shù)樣本所屬于的類(lèi)來(lái)標(biāo)記該節(jié)點(diǎn);(3)節(jié)點(diǎn)的樣本集合中所有樣本的剩余屬性取值完全相同,但所屬類(lèi)別卻不同,此時(shí)用樣本中多數(shù)類(lèi)來(lái)標(biāo)示該節(jié)點(diǎn)。”
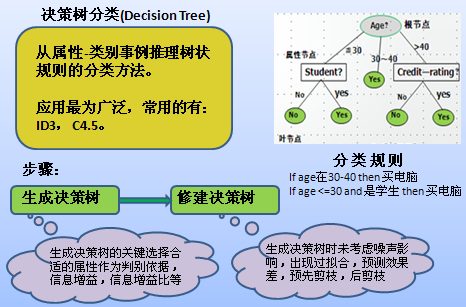
徐教授接著說(shuō):“決策樹(shù)算法的典型代表是ID3(Interactive Dicremiser version 3)算法,它是由Quinlan等人于1986年提出的,是當(dāng)前機(jī)器學(xué)習(xí)領(lǐng)域中最有影響力的算法之一。其核心思想是在決策樹(shù)的構(gòu)建過(guò)程中采取基于信息增益的特征選擇策略,即選取具有最高信息增益的屬性作為當(dāng)前節(jié)點(diǎn)的分裂屬性,使得對(duì)結(jié)果劃分中的樣本分類(lèi)所需要的信息量最小。以此構(gòu)造與訓(xùn)練數(shù)據(jù)一致的一棵決策樹(shù),從而保證了決策樹(shù)具有最小的分支數(shù)量和最小的冗余度。”
李部長(zhǎng):“ID3算法思想簡(jiǎn)單,并且由其構(gòu)造的決策樹(shù)對(duì)樣本的識(shí)別率比較高。在實(shí)際應(yīng)用中,ID3算法還有什么不足之處嗎?”
徐教授按了一下光筆,并說(shuō):“請(qǐng)看大屏幕ID3算法的缺點(diǎn)主要表現(xiàn)在以下幾個(gè)方面。”
ID3算法的不足之處
(1)ID3算法在搜索過(guò)程中不能再回溯重新考慮選擇過(guò)的屬性,從而收斂到局部最優(yōu)解而不是全局最優(yōu)解;
(2)信息增益的度量偏袒于屬性取值數(shù)目較多的屬性,這不太合理;
(3)ID3算法只能處理離散值得屬性,不能處理連續(xù)屬性;
(4)當(dāng)訓(xùn)練樣本過(guò)小或者包含有噪聲的時(shí)候,容易產(chǎn)生過(guò)度擬和(Overfitting)現(xiàn)象。
馬處長(zhǎng)看著屏幕,問(wèn)道:“徐老師,那怎樣改進(jìn)ID3算法呢?”
徐教授回答道:“針對(duì)ID3算法的不足,Quinlan于1993年提出了ID3的改進(jìn)的方法——C4.5。與ID3相比,C4.5主要在以下幾個(gè)方面作了修改,并且引進(jìn)了新的功能:用信息增益比率作為選擇標(biāo)準(zhǔn),彌補(bǔ)了ID3算法偏向于取值較多的屬性的不足;合并連續(xù)屬性的值;可以處理具有缺少屬性值的訓(xùn)練樣本;運(yùn)用不同的剪枝技術(shù)來(lái)避免決策樹(shù)的過(guò)擬合現(xiàn)象;K次交叉驗(yàn)證等等。”
李部長(zhǎng)又問(wèn):“徐老師,我們?cè)谑褂脹Q策樹(shù)算法進(jìn)行分類(lèi)時(shí),有時(shí)會(huì)出現(xiàn)過(guò)擬合現(xiàn)象,這是怎么回事呢?”
徐教授不厭其煩:“基本的決策樹(shù)構(gòu)造算法沒(méi)有考慮噪聲,因此生成的決策樹(shù)可以完全與訓(xùn)練數(shù)據(jù)擬合,也就是說(shuō),對(duì)訓(xùn)練數(shù)據(jù)的測(cè)試準(zhǔn)確度可以達(dá)到100%。但是在有噪聲的情況下,完全擬合將導(dǎo)致“過(guò)擬合”的結(jié)果,即對(duì)訓(xùn)練數(shù)據(jù)的完全擬合反而導(dǎo)致對(duì)新數(shù)據(jù)的預(yù)測(cè)能力下降。這是因?yàn)楫?dāng)訓(xùn)練數(shù)據(jù)集合包含噪聲時(shí),決策樹(shù)在生成的過(guò)程中為了與訓(xùn)練數(shù)據(jù)一致,必然生成了一些反映噪聲的分支,這些分支不僅在新的決策問(wèn)題中導(dǎo)致錯(cuò)誤的預(yù)測(cè),而且增加了模型的復(fù)雜度。”
馬處長(zhǎng)也問(wèn)道:“那怎么避免過(guò)擬合現(xiàn)象呢?”
徐教授:“解決決策樹(shù)生成過(guò)程中的過(guò)擬合問(wèn)題的方法主要是對(duì)決策樹(shù)進(jìn)行剪枝。剪枝是一種克服噪聲的技術(shù),它有助于提高決策樹(shù)對(duì)新數(shù)據(jù)的準(zhǔn)確分類(lèi)能力,同時(shí)能使決策樹(shù)得到簡(jiǎn)化,使其更容易理解,加快分類(lèi)速度。剪枝策略可分為預(yù)剪枝(pre-pruning)和后剪枝(post-pruning)兩種。預(yù)剪枝主要是通過(guò)建立某些規(guī)則限制決策樹(shù)的充分生長(zhǎng),后剪枝則是等決策樹(shù)充分生長(zhǎng)完畢后再剪去那些不具有一般代表性的葉節(jié)點(diǎn)或者分枝。盡管前一種方法可能看起來(lái)更直接,但是后一種方法在實(shí)踐中更成功。因此在實(shí)際運(yùn)用中更多的采用的是后剪枝技術(shù)。”





























建設(shè)實(shí)踐")
字化轉(zhuǎn)型的四大典型場(chǎng)景,TempoBI來(lái)支持")
據(jù)分析上手難?2招幫你快速生成高質(zhì)量數(shù)據(jù)可視化報(bào)表")



 Tempo商業(yè)智能平臺(tái)
Tempo商業(yè)智能平臺(tái) Tempo人工智能平臺(tái)
Tempo人工智能平臺(tái) Tempo數(shù)據(jù)工廠平臺(tái)
Tempo數(shù)據(jù)工廠平臺(tái) Tempo指標(biāo)平臺(tái)
Tempo指標(biāo)平臺(tái) Tempo數(shù)據(jù)治理平臺(tái)
Tempo數(shù)據(jù)治理平臺(tái) Tempo主數(shù)據(jù)管理平臺(tái)
Tempo主數(shù)據(jù)管理平臺(tái)

 陜公網(wǎng)安備 61019002000171號(hào)
陜公網(wǎng)安備 61019002000171號(hào)




