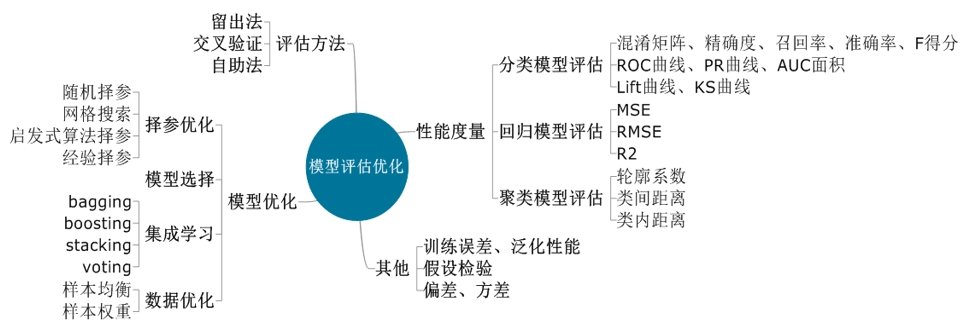
模型評估在滿足業務分析目標的前提下堅持優先選擇簡單化的模型作為準則。在每個分析場景中,我們可以基于不同的算法構建多個模型,并通過模型優化的方法體系對其進行訓練優化。然而,當訓練得到多個模型時,我們需要確定如何選擇最優模型。這可以基于性能度量作為指標體系,并依據一定的評估方法進行擇優選擇。
平臺針對分類、回歸、聚類、時序等機器學習算法提供了自動擇參節點。在實際建模中,對于每個算法,平臺提供一批參數及其多個取值。我們可以根據這些參數和設置的參數值進行組合,通過循環執行組合內的值,節點會自動返回表現最佳的模型。
在需要擇參的參數維度較高且要求速度快精度較高的場景中,可以使用隨機擇參方法。而在需要擇參的參數維度較高,且要求速度快精度相對不高的場景中,貝葉斯擇參方法更為合適。
平臺還提供了集成學習節點,包括bagging回歸、bagging分類、voting回歸和voting分類。這些節點可用于分類問題集成和回歸問題集成,以得到更好和更全面的強監督模型。
為了解決分類模型和回歸模型的泛化問題,平臺分別提供了分類交叉驗證節點和回歸交叉驗證節點。這些節點有助于從候選模型中選擇最適合特定學習問題的模型,并幫助確定參數,以在偏差和方差之間找到最佳平衡點。
為了更加方便和快速進行模型優化,平臺還提供了斷點緩存功能。斷點功能允許流程從開頭執行到指定的節點,而緩存功能在流程第一遍執行時保存當前節點的執行結果。這樣,在第二次執行流程時,可以從有緩存的節點處開始執行,避免每次都從流程的起點開始執行,提高建模效率和用戶體驗。
值得注意的是,在模型評估和優化完成后,我們需要在實際業務上對模型進行驗證,以判斷它們是否符合實際業務情況。只有通過實際業務驗證的模型才能真正投入使用。這個驗證步驟是確保模型質量的關鍵環節。
為了確保模型的質量,模型評估和優化之后需要進行實際業務驗證。實際業務驗證是將模型與實際業務數據進行對比和驗證,以確保模型的準確性和適用性。只有經過實際業務驗證的模型才能真正投入使用,并為業務決策和問題解決提供有力支持。
在實際業務驗證過程中,需要考慮以下幾個關鍵因素:
1. 數據的質量和偏差:確保驗證數據集的質量和真實性,避免數據偏差對模型驗證結果的影響。
2. 模型的預測性能:比較模型的預測結果與實際數據的差異,評估模型的預測準確性和誤差范圍。可以使用各種度量指標,如準確率、召回率、精確度、F1值等來評估模型的性能。
3. 模型的穩定性和可靠性:驗證模型在不同數據樣本和場景下的穩定性和可靠性。這可以通過使用交叉驗證或在不同時間段內進行驗證來實現。
4. 模型與業務目標的對齊程度:驗證模型是否能夠滿足業務分析目標和需求,是否能夠幫助解決實際業務問題。
5. 模型的解釋性和可解釋性:評估模型的解釋性和可解釋性,確保模型的結果和決策過程可以被理解和解釋。
在實際業務驗證中應該進行全面而系統的評估,對模型的各個方面進行綜合考量,以幫助提高模型的質量和可靠性。
此外,模型的優化和改進也是一個持續的過程。通過不斷收集和分析實際業務反饋,可以發現模型存在的問題并進行相應的調整和改進。模型的優化是一個迭代的過程,隨著業務的演變和數據的變化,需要不斷更新和優化模型,以保持其有效性和適應性。
因此,在模型評估和優化完成后,實際業務驗證以及持續的模型優化和改進都是確保模型質量的重要環節。通過這些步驟,可以提高模型的準確性、穩定性和可靠性,為業務決策和問題解決提供更可靠的支持和指導。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺








 陜公網安備 61019002000171號
陜公網安備 61019002000171號



