時間序列數據挖掘:利用機器學習揭示趨勢和模式
2023-12-14 16:17:00
次
隨著數據技術的不斷發展和普及,數據分析和數據挖掘成為了企業和組織在日常運營和戰略決策中不可或缺的工具。而時間序列分析,作為一種重要的數據分析和數據挖掘方法,已經被廣泛應用于各個領域,如金融、經濟、市場營銷等。通過對時間序列數據的分析,可以發現潛在的規律和趨勢,幫助決策者更準確地預測未來市場走向、評估風險和機會,制定更加優化的戰略或運營計劃。本文將介紹時間序列分析的基本概念和方法,以及如何利用數據分析、數據挖掘等技術對這種方法進行優化和改進。
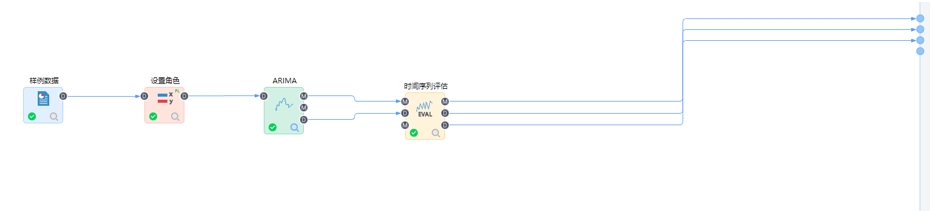
第一步接入數據:
時間序列算法要求接入結構化數據,自變量數據類型為數值型,不支持字符型、日期型和文本型等。若接入的自變量數據不滿足時間序列分析的數據要求,可以通過屬性變化節點進行數據類型轉換或重新接入數據。
第二步設置角色:
通過設置角色節點確定時間序列分析研究的屬性列,設置為自變量。時間序列算法必須設置自變量,不支持設置因變量,自變量僅支持連續型(數值)屬性,并且只能有一個自變量。
一般建議在設置角色之前先進行數據的可視化探索,利用平臺提供的圖表分析節點,如散點圖等識別序列是否是非隨機序列,如果是非隨機序列,則觀察其平穩性。對非平穩的時間序列數據采用差分進行平穩化處理,直到處理后序列是平穩的非隨機序列。因為對于時間序列數據,最重要的檢驗就是時間序列數據是否為白噪聲數據、時間序列數據是否平穩,以及對時間序列數據的自相關系數和偏自相關系數進行分析。如果時間序列數據是白噪聲數據, 說明其沒有任何有用的信息。針對時間序列數據的很多分析方法,都要求所研究的時間序列數據是平穩的,所以判斷時間序列數據是否平穩,以及如何將非平穩的時間序列數據轉化為平穩序列數據,對時間序列數據的建模研究是非常重要的,如果模型沒有通過檢驗(檢驗模型殘差序列是否為白噪聲序列),需要對其進行重新識別。
第三步建立數據分析模型:
根據業務分析方案和所識別出來的特征建立相應的時間序列模型。平臺內置9種時間序列算法可以直接拖拽使用,并配置對應的模型參數,包括:ARIMA、稀疏時間序列、指數平滑、移動平均、向量自回歸、X11、X12、回聲狀態網絡和灰色預測。當我們不清楚當前數據更適合哪種時間序列算法,或不清楚多個模型中哪個模型效果更好時,我們有兩種處理方案:方案一,通過多分支節點將自變量相同的輸入數據同時傳遞給多個不同的時間序列模型,由平臺推薦出多個模型中的最優模型;第二種,通過自動時序節點選擇多個時間序列算法一次性構建模型,該節點內嵌自動擇參功能,將多個算法及其對應的多組參數生成的多個模型進行評估比較,最終幫助我們推薦出最佳算法及相應的最佳參數組合。
第四步數據分析模型評估:
利用時間序列評估節點檢驗時序模型的可靠性,在洞察中根據一些評價的指標(如相對誤差等指標)或者圖表展示,獲得質量最佳的時序模型。
完成上述建模之后執行流程,流程執行成功后自動跳轉至洞察頁面,在洞察頁面點擊可以查看模型的分析結果,我們通過示例流程來詳細介紹。點擊【ARIMA】查看模型結果,包含預測值真實值對比曲線圖、自相關圖、偏相關圖及統計檢驗量。

點擊【時間序列模型評估】查看模型對歷史數據預測的評估如下:
從誤差來看,模型的平均相對誤差為19%,所以模型結果比較一般。再來看數據集的情況,可以看到新增的prediction預測結果列。
第五步利用算法模型預測:
需要注意的是,平臺中時間序列的模型不支持連接模型利用節點,對于新數據只能重新進行預測。那么在上述示例中模型構建完成后,就可以利用模型對系統容量進行預測,其模型應用過程如下:
1、從系統中每日定時抽取服務器磁盤數據;
2、對定時抽取的數據進行清洗、數據變換預處理等操作;
3、將預處理后的數據存放到數據庫中,定時的調用流程對服務器磁盤進行預測,預測后四天的磁盤使用大小;
4、將預測值與磁盤的總容量比較,獲得預測的磁盤使用率。如果某一天預測的使用率達到業務設置的預警級別,就會以預警的方式提醒系統管理員。





























 Tempo商業智能平臺
Tempo商業智能平臺 Tempo人工智能平臺
Tempo人工智能平臺 Tempo數據工廠平臺
Tempo數據工廠平臺 Tempo指標平臺
Tempo指標平臺 Tempo數據治理平臺
Tempo數據治理平臺 Tempo主數據管理平臺
Tempo主數據管理平臺





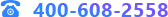




 陜公網安備 61019002000171號
陜公網安備 61019002000171號



